DagoBERT: 사전 훈련된 언어 모델로 파생 형태 생성
Valentin Hofmann, Janet B. Pierrehumbert, 힌리히 슈체
2020년 10월 7일
Syntax와 Semantics보다는 Derivational Morphology
이러한 모든 언어 지식 중에서 구문 및 의미론이 NLP에서 각광을 받았습니다. 이 논문은 BERT의 파생 형태학적 기능에 대한 연구를 제시하며 DagoBERT라는 완전히 미세 조정된 모델을 제안합니다. 그것은 도함수를 예측하는 파생 생성(DG) 작업에서 최신 기술을 능가합니다. “착용불가” 주어진 영어 클로즈 문장 “이 재킷은 _” 그리고 기지 “입다”. 본 연구는 (1) 사전 훈련된 언어 모델의 언어 능력에 대한 선행 연구가 부족하고, BERT가 생성하는 하위 단어 단위가 대부분 파생 접사라는 사실은 형태에 대한 풍부한 지식을 나타냅니다. (2) 파생 생성(DG) 작업 자체.
언어학은 형태론을 굴절과 파생으로 나눕니다. DG의 관점에서 볼 때 그들 사이에는 두 가지 차이점이 있습니다. 첫째, 파생은 의미의 더 넓은 스펙트럼을 다루기 때문에 예측 일반적으로 그들 중 특정 호환 어휘소가 불가능한 것은 무엇입니까? 둘째, 형태와 의미의 관계는 파생에서 많이 다릅니다. 파생의 이러한 특징은 의미에서 형성까지의 학습 기능을 훨씬 더 어렵게 만듭니다.
다고BERT
데이터 세트는 (1) 변경된(파생을 가린) 문장, (2) 파생어, (3) 문장이 태그보다 파생 형태에 내재된 의미적 가변성을 더 잘 반영하므로 기본 항목으로 구성됩니다. 데이터 세트는 공개적으로 사용 가능한 모든 Reddit 게시물에서 48개의 생산적인 접두사, 44개의 생산적인 접미사 및 20,259개의 기반을 기반으로 생성됩니다. 또한 작업은 (1) P(접두사가 하나인 파생어), (2) S(접미사가 하나인 파생어) 및 (3) PS(접두어와 접미사가 하나인 파생어)의 세 가지 경우로 제한됩니다. 서로 다른 언어적 특성을 가지고 있는 것으로 알려져 있습니다.
작업은 다음과 같이 다시 작성할 수 있습니다.
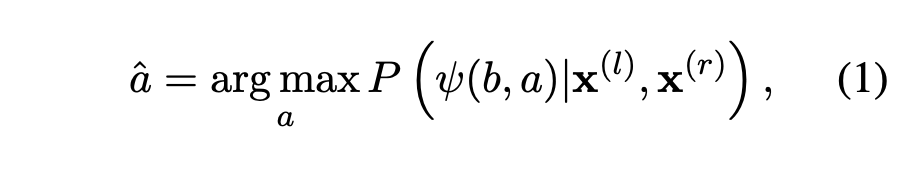
BERT의 어휘에는 단어 내부에 형성된 토큰이 없기 때문에 이 논문은 네 가지 외부 세분화 방법을 테스트했으며 그 방법 중 우울 (접두사와 기본 사이에 하이픈 삽입)을 채택했습니다. 이 논문은 미세 조정 DCL(Derivational Classification Layer), BERT 모델 자체 및 둘 다의 사용 상태에 따라 몇 가지 BERT 모델과 기준선을 조사했습니다. DagoBERT(Derivationally And Generatively Optimized BERT)는 DCL과 모델을 모두 미세 조정하는 모델입니다. DG 작업에 대한 이전의 최신 모델이었던 기준선 중 하나는 LSTM입니다. POS(Part Of the Speech)가 알려지면 LSTM이 더 잘 수행되지만 이 경우 논문에서는 주어진 POS 설정을 고려하지 않습니다.
전반적인 성능 및 해석
DagoBERT는 기본적으로 모든 설정 P, S 및 PS에 대해 BERT, BERT+(DG에서 DCL만 교육) 및 LSTM을 능가합니다. 한편 DagoBERT는 두 개의 마스킹된 토큰 사이의 통계적 종속성을 학습할 수 없기 때문에 P와 S를 설정하는 데 있어 DagoBERT와 다른 모델 간의 성능 차이가 더 큽니다.
나아가 잘못된 예측의 패턴에 대해서도 심도 있게 분석했다. 이러한 예측 중에서 그들은 두 가지 흥미로운 측면을 발견했습니다. 우선, 공통 POS가 있는 그룹으로 충분이 클러스터되었습니다. 이것은 DagoBERT가 잘못된 접사를 예측하더라도 의미론적으로나 구문론적으로 ground truth와 일치하는 접사를 예측하는 경향이 있음을 나타냅니다. 둘째, DagoBERT는 같은 척도에서 혼동하지만 반의어입니다. 이것은 BERT가 부정 표현에 어려움을 겪는 최근 논문과 관련이 있습니다.
마지막으로 이 백서에서는 입력 세분화의 영향에 대해 논의했습니다. 그들은 경험적으로 형태학적으로 올바른 분할, 우울지속적으로 WordPiece 토큰화를 능가합니다. 따라서 이는 (1) 세분화가 얼마나 많은 파생 지식을 학습할 수 있는지에 영향을 미치고 (2) 형태학적으로 유효하지 않은 세분화로 인해 BERT가 의미론적으로 관련 없는 단어가 유사한 표현을 갖도록 강제한다는 것을 나타냅니다.
언어학과 컴퓨터 과학은 어디에서 만나나요?
최근 언어학을 공부하는 사람들은 NLP에서 컴퓨터 과학 학생들과 경쟁하기 시작했습니다. 처음에는 데이터만 관리했지만 NLP에서 언어 지식이 중요해지면서 이제는 더 높은 성능을 얻기 위해 BERT와 같은 모델을 수정하고 있습니다. 이 현상은 그들이 가지고 있는 실제 지식이 작업별 모델이 최신 기술을 달성하도록 만들고 있기 때문에 매우 긍정적으로 보입니다.