Google NetThesis
논문 요약
이 아키텍처의 주요 기능은 네트워크 내 컴퓨팅 리소스의 향상된 활용입니다.
네트워크에서 컴퓨팅 리소스의 효율성을 높여야 합니다.
이것은 컴퓨팅 예산을 일정하게 유지하면서 네트워크의 깊이와 폭을 증가시킬 수 있는 세심하게 제작된 설계를 통해 달성되었습니다.
이전 모델은 깊이에만 신경을 썼고 Googlenet은 깊이와 넓이에만 신경을 쓴 것을 볼 수 있습니다.
분류 및 탐지의 일부로 품질이 평가되는 22계층 심층 네트워크
Googlenet은 22개의 레이어를 쌓았습니다.
본문

모델을 깊고 효율적으로 구축하고 싶고 깊이와 폭을 언급합니다.

Alexnet은 7×7 필터를 사용했지만 vggnet 작성자는 3×3 필터가 7×7보다 효율적이라고 생각하여 3×3 필터를 사용했습니다.
googlenet은 처음에 7×7 필터를 사용합니다(스티커 부분을 통과하세요!).
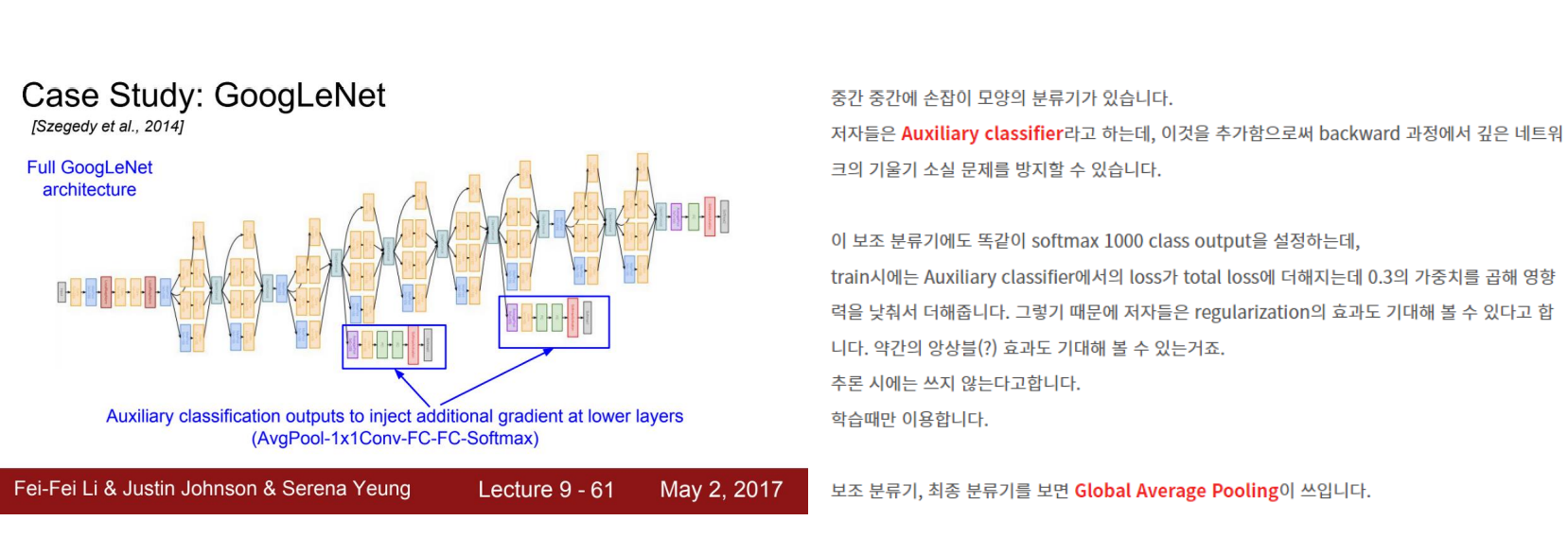
보조 분류기: 보조 분류기
원래는 마지막에 손실만 처리하기 위해 마지막에 softmax를 사용했지만, Googlenet은 중간에 손실을 처리하기 위해 보조 분류기를 사용했습니다.
Flatten은 vgg까지 사용되었지만 googlenet은 Global Average Pooling을 사용합니다.
전역 평균 풀링: 필터 크기 값으로 평균화(특징을 1차원 벡터로 변환)
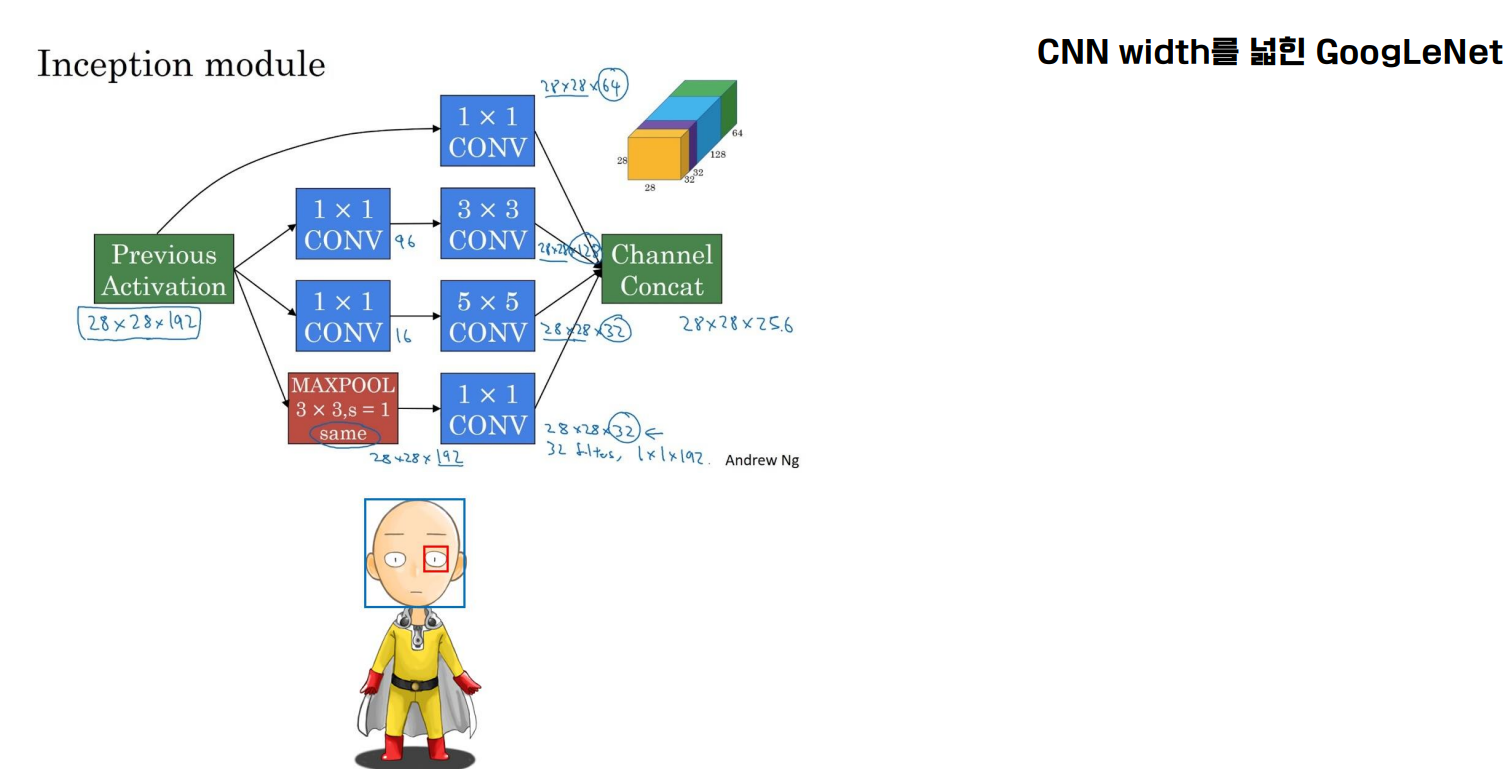
파란색 사각형(얼굴)이 5 x 5이고 빨간색 사각형(눈)이 3 x 3이라고 합시다. 3 x 3을 사용하면 디테일한 물체를 잘 볼 수 있습니다.
그러나 얼굴과 같은 큰 개체의 경우 5×5가 3×3보다 더 좋아 보입니다. 3×3을 사용하면 정보 다양화가 손실됩니다.
작은 필터만 사용하면 큰 개체를 포함하기 어렵습니다.
그래서 그림을 보면 3×3과 5×5도 같이 사용되는 것을 볼 수 있습니다.
Googlenet은 컴퓨팅 리소스에 대해 우려했지만 vggnet은 3×3 필터가 효율적임을 발견했습니다. 그러나 위의 그림과 같이 5×5도 사용해야 하므로 많은 계산 리소스를 소비하게 됩니다. 따라서 Googlenet은 효율적인 컴퓨팅 리소스를 위해 1x1conv를 사용합니다. (1x1conv를 사용하면 채널축의 크기를 감당할 수 있다. 1x1conv는 1x1conv가 하나씩 보기 때문에 객체를 캡쳐하는 데 포인트는 없지만 비선형성이 있다. 192채널이 한 장이다. 그래서 값은 정렬.)
3×3 및 5×5를 효율적으로 사용할 수 있습니다. <- 다른 정보를 얻으려면 너비를 확장하십시오.
매개변수 요약
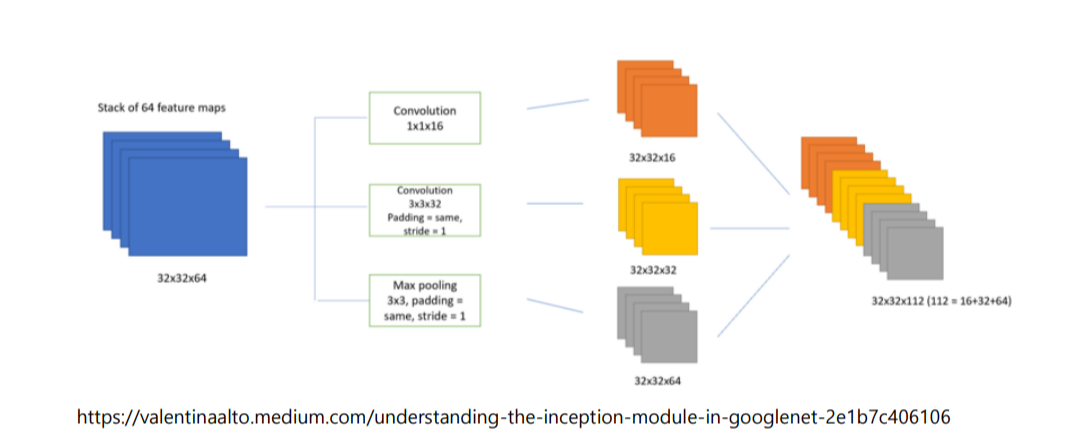
순진하고 차원이 축소된 Inception 모듈 버전

1x1conv를 효율적으로 사용하면 매개변수의 수가 크게 줄어듭니다.
결론: Googlenet은 1x1conv를 사용하여 깊이와 넓이에 주의를 기울인다는 것을 보여주었습니다.